Pandas 데이터프레임에서 열의 평균, 표준편차 및 Cpk 값을 구하는 방법을 알려드리겠습니다.
Cpk는 품질 관리에서 프로세스 능력 지수로 사용되며, 공정이 목표값과 얼마나 일치하는지 평가하는 지표입니다.
샘플 데이터프레임
먼저, 다음과 같은 샘플 데이터프레임을 사용하여 예시를 설명하겠습니다.
import pandas as pd
import numpy as np
# 샘플 데이터프레임 생성
data = {'Value': [10, 12, 9, 11, 13, 8, 10, 12, 9, 11]}
df = pd.DataFrame(data)열의 평균 구하기
Pandas의 mean() 함수를 사용하여 열의 평균을 계산할 수 있습니다.
다음은 ‘Value’ 열의 평균을 구하는 예제입니다.
mean_value = df['Value'].mean()
print("평균:", mean_value)열의 표준편차 구하기
Pandas의 std() 함수를 사용하여 열의 표준편차를 계산할 수 있습니다.
다음은 ‘Value’ 열의 표준편차를 구하는 예제입니다.
std_value = df['Value'].std()
print("표준편차:", std_value)Cpk 구하기
Cpk 값은 공정의 불량률과 규격 한계의 차이를 고려하여 계산됩니다.
Cpk는 다음과 같은 공식을 사용하여 계산할 수 있습니다.
Cpk = min((USL - mean_value) / (3 * std_value), (mean_value - LSL) / (3 * std_value))여기서, USL은 상한 한계값(최대 허용치), LSL은 하한 한계값(최소 허용치)를 나타냅니다.
예를 들어, USL이 15, LSL이 5인 경우 Cpk 값을 계산하는 예제는 다음과 같습니다.
USL = 15
LSL = 5
Cpk = min((USL - mean_value) / (3 * std_value), (mean_value - LSL) / (3 * std_value))
print("Cpk:", Cpk)출력 결과
평균: 10.5
표준편차: 1.5811388300841898
Cpk: 0.9486832980505138위의 예제에서는 ‘Value’ 열의 평균과 표준편차를 계산한 후, Cpk 값을 구하는 방법을 보여주고 있습니다.
Cpk 값은 공정의 능력을 평가하는데 사용되며, 값이 1보다 크면 공정이 목표치와 얼마나 가까운지를 나타냅니다.
값이 1보다 작거나 음수인 경우에는 공정의 능력이 부족함을 나타냅니다.
Pandas 데이터프레임을 상자 그림으로 나타내고 평균, 표준편차, Cpk 표시하기
예시로 제공된 데이터프레임을 상자 그림(boxplot)으로 나타내고 평균, 표준편차, Cpk 데이터를 플롯에 표시하는 방법은 다음과 같습니다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 샘플 데이터프레임 생성
data = {'Value': [10, 12, 9, 11, 13, 8, 10, 12, 9, 11]}
df = pd.DataFrame(data)
# 박스 플롯 그리기
plt.figure(figsize=(8, 6))
sns.boxplot(data=df, y='Value')
plt.title('Box Plot')
plt.xlabel('Value')
# 평균, 표준편차, CpK 값 계산
mean_value = df['Value'].mean()
std_value = df['Value'].std()
USL = 15
LSL = 5
Cpk = min((USL - mean_value) / (3 * std_value), (mean_value - LSL) / (3 * std_value))
# 평균, 표준편차, CpK 값 플롯에 표시
plt.axhline(mean_value, color='r', linestyle='--', label='Mean')
plt.text(0.05, mean_value + 0.2, f'Mean: {mean_value:.2f}', color='r')
plt.axhline(mean_value + std_value, color='g', linestyle='--', label='Std')
plt.text(0.05, mean_value + std_value + 0.2, f'Std: {std_value:.2f}', color='g')
plt.text(0.05, mean_value + std_value + 0.4, f'Cpk: {Cpk:.2f}', color='b')
# 범례 표시
plt.legend()
# 그래프 출력
plt.show()결과 출력
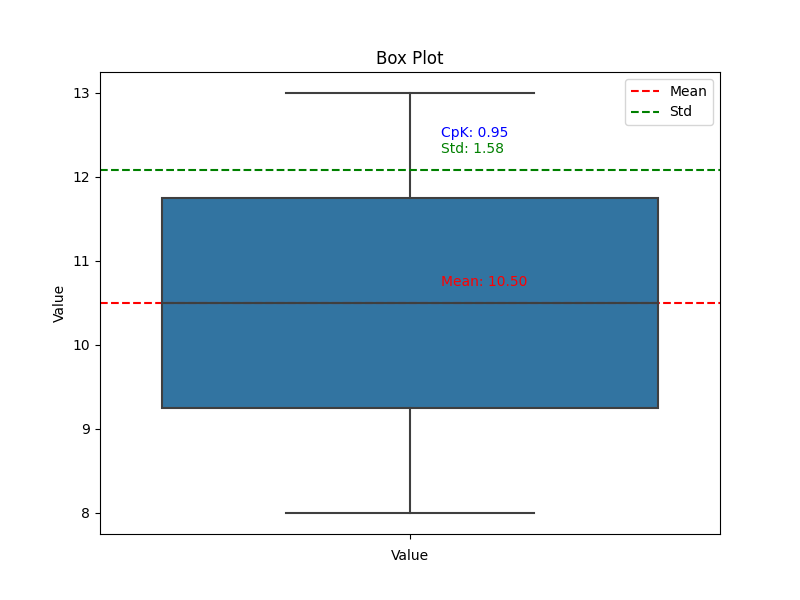
위의 코드는 데이터프레임을 박스 플롯으로 그리고 평균, 표준편차, Cpk 값을 플롯에 표시하는 방법을 보여줍니다. sns.boxplot() 함수를 사용하여 데이터프레임의 ‘Value’ 열을 기반으로 박스 플롯을 그립니다.
평균, 표준편차, Cpk 값을 계산한 후 plt.axhline() 함수를 사용하여 해당 값을 플롯에 수평선으로 표시합니다. plt.text() 함수를 사용하여 플롯 내에 평균, 표준편차, Cpk 값을 텍스트로 표시합니다.
마지막으로, plt.legend() 함수를 사용하여 범례를 표시하고 plt.show() 함수를 호출하여 그래프를 출력합니다.
이를 통해 데이터프레임의 분포를 시각화하고 동시에 평균, 표준편차, Cpk 값을 플롯에 표시하여 데이터의 품질과 공정 능력을 평가할 수 있습니다.
![[Python] 11. Pandas 데이터프레임 Excel 읽고 쓰기](https://coldbrown.co.kr/wp-content/uploads/2023/07/Python-11.-Pandas-데이터프레임-Excel-읽고-쓰기.png)
![[Python] 09. Seaborn 여러 개의 plot 한번에 그리기](https://coldbrown.co.kr/wp-content/uploads/2023/07/Python-09.-Seaborn-여러-개의-plot-한번에-그리기-150x150.png)
![[Python] 04. Pandas 데이터프레임 누락된 데이터 처리하기](https://coldbrown.co.kr/wp-content/uploads/2023/07/Python-04.-Pandas-데이터프레임-누락된-데이터-처리하기-150x150.png)
![[Python] 12. Pandas 데이터프레임 시각화 함수 만들어 사용하기](https://coldbrown.co.kr/wp-content/uploads/2023/07/Python-12.-Pandas-데이터프레임-시각화-함수-만들어-사용하기-150x150.png)
![[Python] 08. Seaborn sns.set()을 통해 스타일 설정하기](https://coldbrown.co.kr/wp-content/uploads/2023/07/Python-08.-Seaborn-sns.set을-통해-스타일-설정하기-150x150.png)